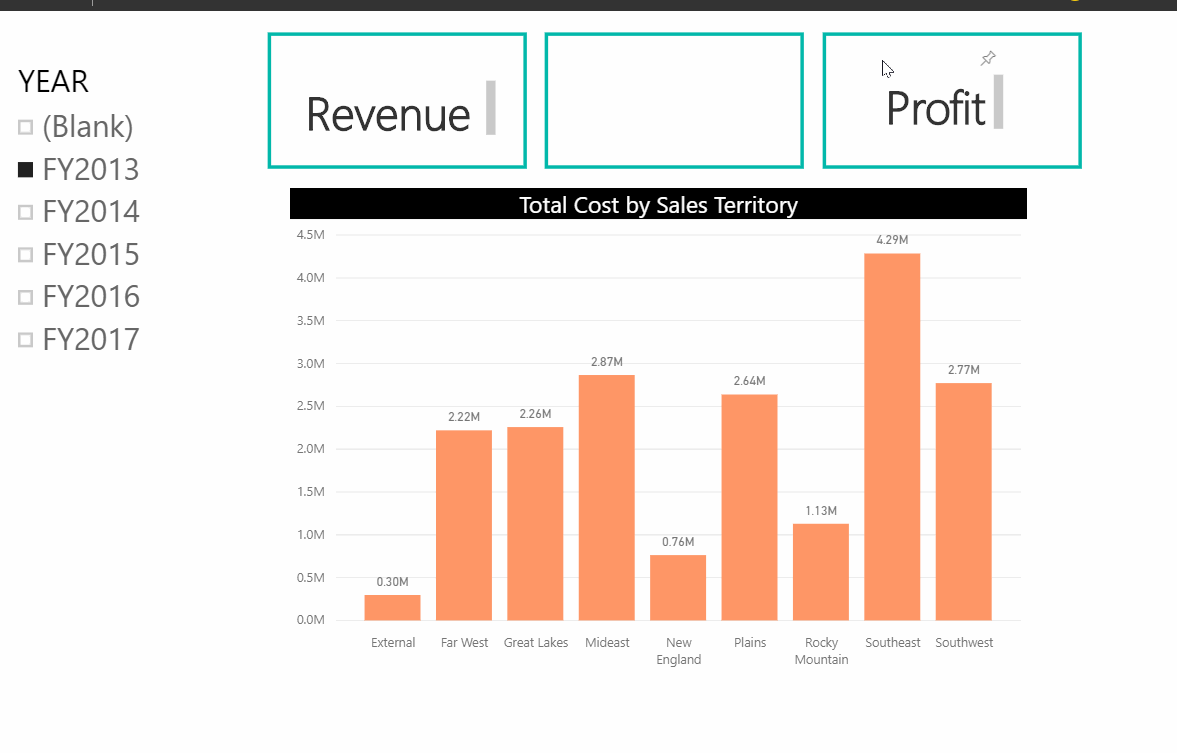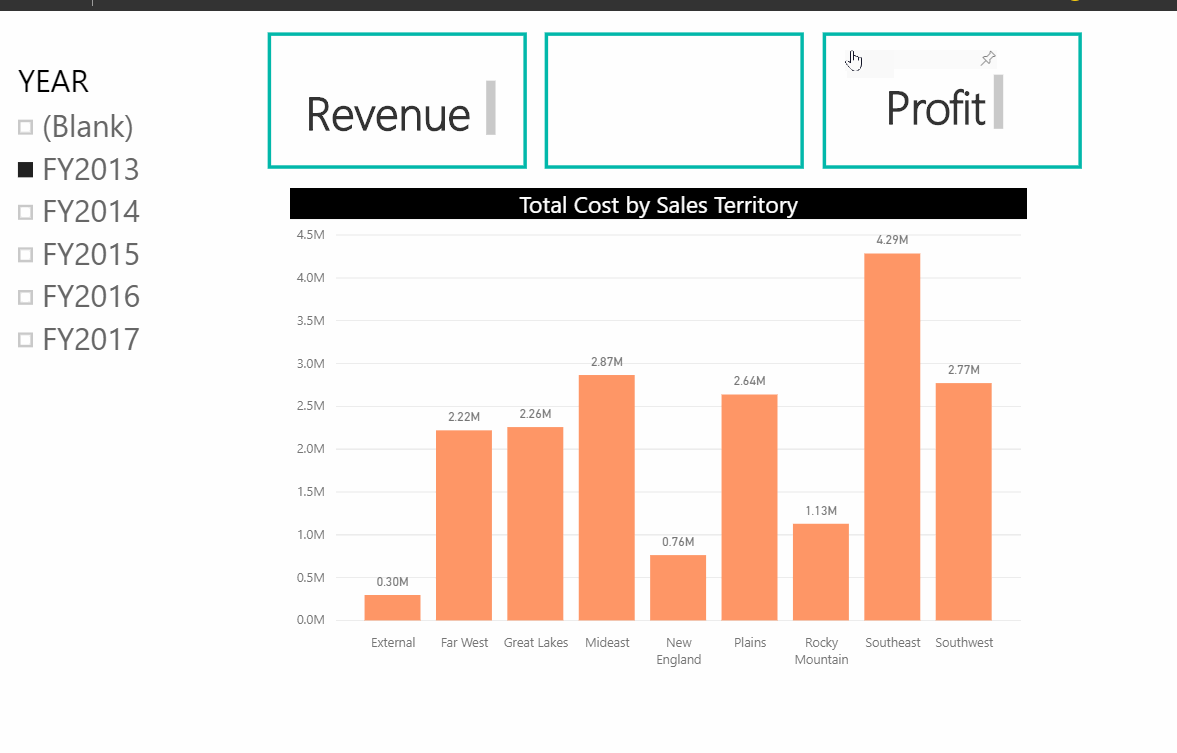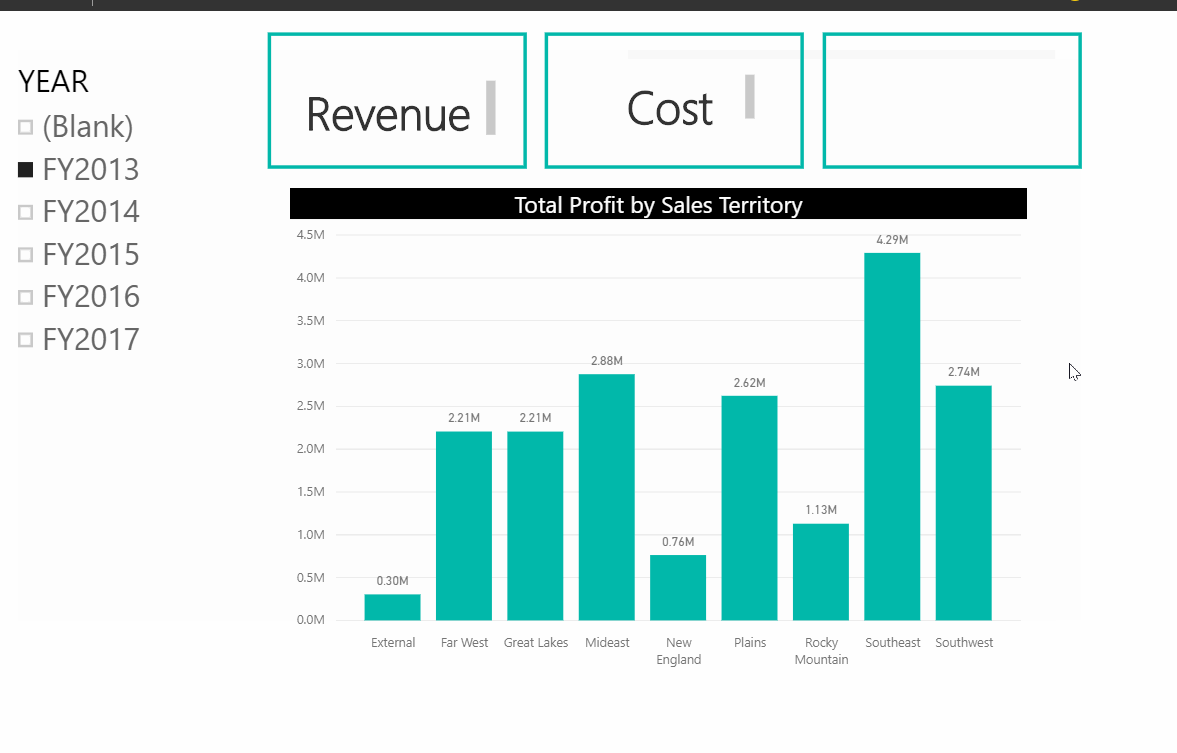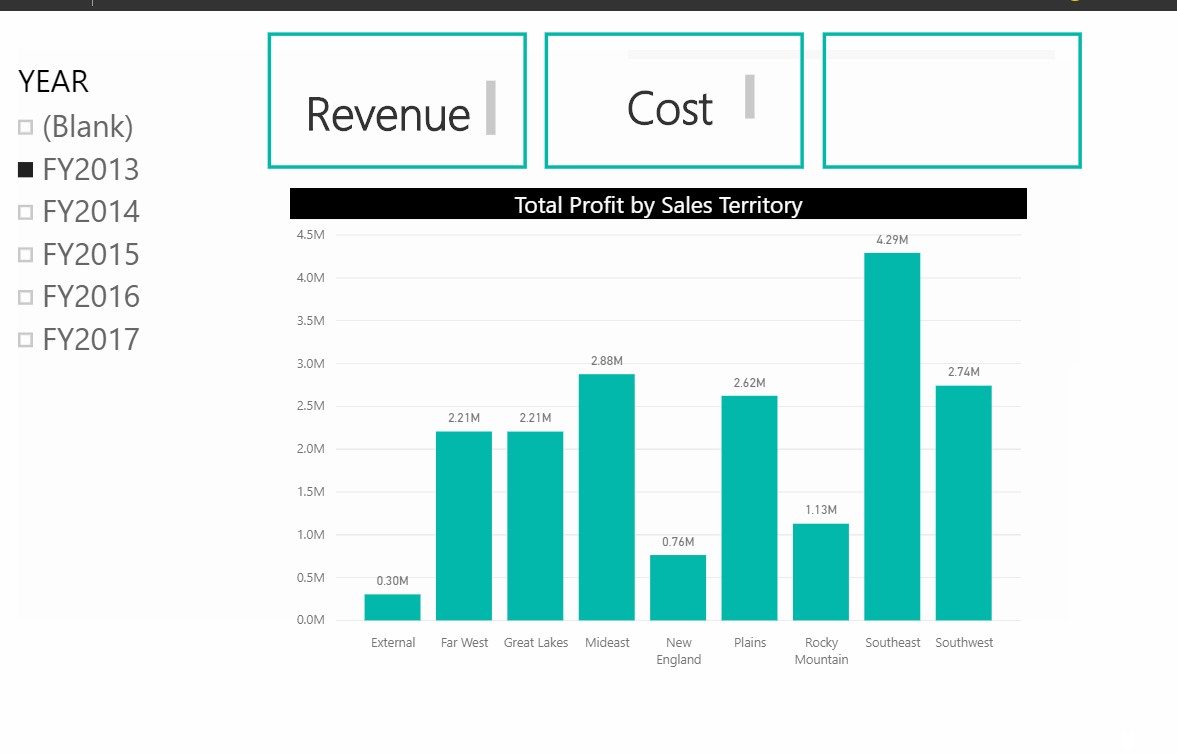
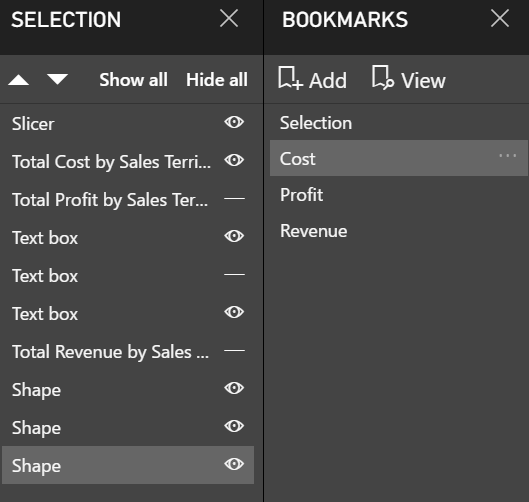
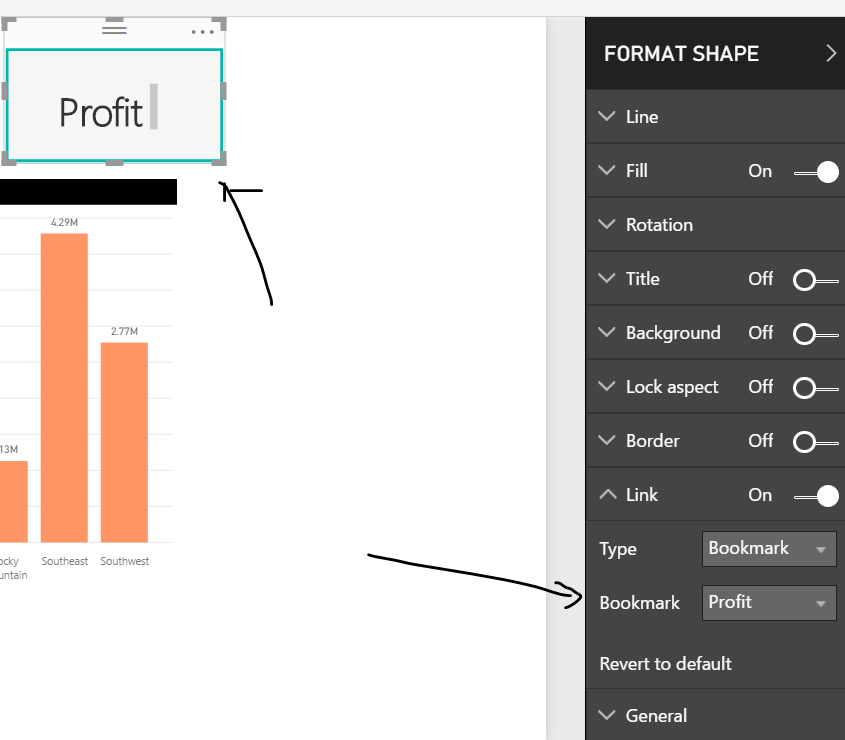
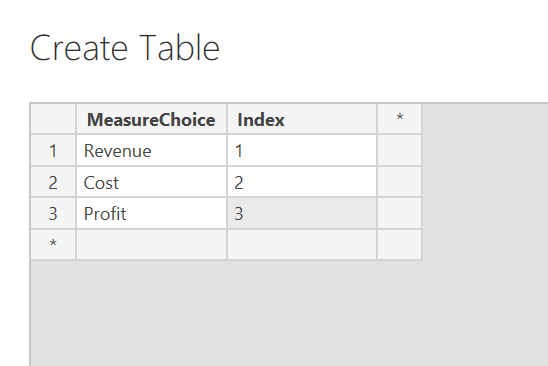
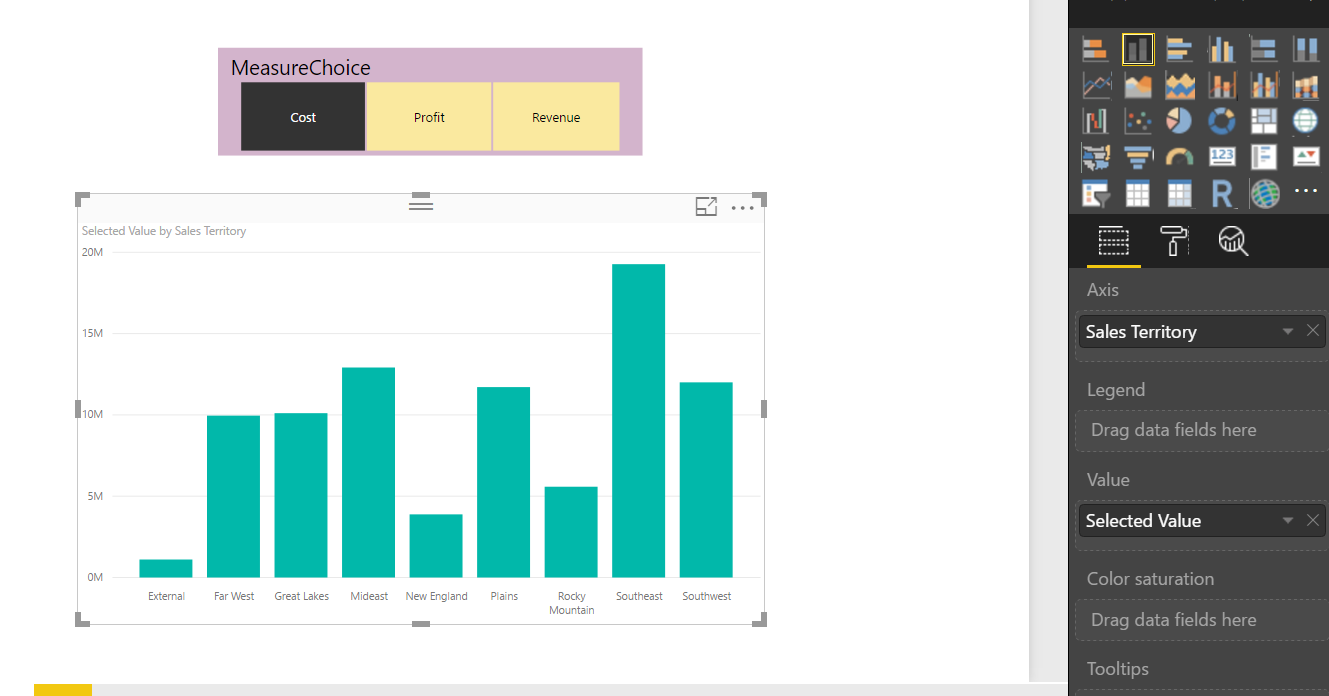
Power BI in itself has a lot of features and functionalities which help you with your job or business. However, Power BI itself won’t solve all your problems which in some cases you may want to peer with other services.
Power BI Premium Capacity
By default, most people will use Power BI pro license level. But when should you consider to leverage Power BI premium capacity? There are couple of things you may need to consider: 1. to store larger datasets, 2. Allow faster DirectQuery /Live Connection query, 3. Support Paginated Reports, 4. Allow unlimited Content Sharing for both internal or external viewers.
If you want to know more information about Power BI Premium Service, please refer to this Microsoft doc.
Azure Synapse Analytics
Azure Synapse Analytics (ASA) is a great alternative for your Power BI model Development. It allow you to query petabytes of data in a performant way with reasonable price by leveraging Direct Query mode of Power BI. ASA Data Pool is a MPP(Massive parallel processing) solution with the Result Set Catches and Materialized View built in so that it enabled high volumes of concurrency quires. Build your data warehouse in ASA as compare to Power BI you can provide Enterprise-grade data preparation and data warehousing solution which allows single source of trues for Power BI and other application and centralized security. In addition, the studio experience within ASA allow team collaboration amongst (data scientists, data engineers, DBA, and BI Developers).
For more information about this topic, please refer to this whitepaper.
AI and Machine Learning Services
There are 3 ways you can extend your BI data to AI insights within Power BI.
1. Auto ML in Power BI Dataflow; Official Doc Tutorial
2. Calling Existing Cognitive Services; Official Doc Tutorial
3. Call Machine Learning Models which Stored in Azure Machine Learning Services. Official Doc Tutorial
Azure Data Lake Storage Gen 2
By default, data used with Power BI is stored in internal storage provided by Power BI. With the integration of dataflows and Azure Data Lake Storage Gen2 (ADLS Gen2), you can store your dataflows in your organization’s Azure Data Lake Storage Gen2 account.
Simple put, Dataflow within power bi is Power Query + Common Data Model (CDM). With the Common Data Model (CDM), organizations can use a data format that provides semantic consistency across applications and deployments. And with Azure Data Lake Storage gen2 (ADLS Gen2), fine-grained access and authorization control can be applied to data lakes in Azure.
For more information about this topic, please refer to this official doc.
Azure Analysis Service
The core data modeling part of Power BI is actually Analysis Services. So using Azure Analysis Services (AAS), you can create data models independently from Power BI services. Right now the largest SKU of AAS allows you to store up to 400GB of data. You can allow different report applications (like Power BI, Tableau, Excel) to connect to your AAS models. Within Microsoft, The Analysis Services team is a sub team of Power BI. The product roadmap for Power BI is to minimize the data modeling experience between Power BI premium capacity and Azure Analysis services. That’s why are are seeing the recent updates from Power BI included those enterprise grade data modeling capability such as increased dataset limited, XMLA endpoint, and workflow pipeline, etc. However, most of those features are in preview and is about to go GA. In short, if you are migrating from your on premise SSAS model to Azure or you do not want to wait for the PBI features go to GA, then AAS is your easiest option. Otherwise, choose Power BI premium to host your reports and data models is strongly recommended.
Reference: https://azure.microsoft.com/en-us/services/analysis-services/#overview
Power Automate & Power App
When I think about Power BI with other Power Platform tools, I think it is a Insights + Action Play. You can use Power BI to get insights from your data and then use Power Automate or Power App to take action out of it.
The Bi-Directional Connectors allow you to connect the services between each other which means you can embed power bi report to power app and you can embed power app to power bi.
Reference:
2. https://powerbi.microsoft.com/en-us/blog/power-bi-tile-in-powerapps
Azure Logic Apps, Azure Monitor log analytics
•Synchronously Refreshing a Power BI Dataset using Azure Logic Apps.
Reference: A Step by Step Community Blog Post.
•Use Power BI to understand your Logic Apps Consumption Data
Reference: A Microsoft Blog
•Use Azure Monitor Logs you can understand your Power BI embedded consumption. You can also use Power BI to create customized report out of your Azure Monitor Logs.
Reference: Microsoft Doc
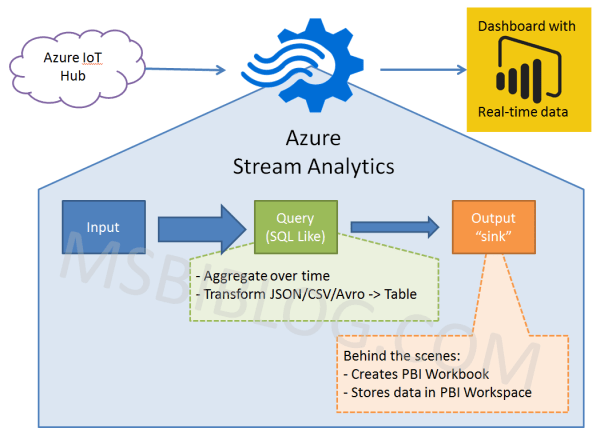
Azure Streaming Analytics
This is a solution for true real time analytics in Power BI. It enables you to visualize your IOT or Events data.
Typical Architectural is Device Data -> Event Hub -> Azure Streaming Analytics -> Power BI Streaming Datasets -> Power BI Dashboards.
Reference: Official Document
My blog: https://xuanalytics.com/2019/03/24/simulated-streaming-data-power-bi-embedded/
Microsoft Teams
You can Add your Power BI report as an App to Teams.
Reference: Official Doc
Also if you have admin credentials to Teams, then you can Analyze Call Quality Data in Power BI.
Reference: Official Doc
Dynamics 365
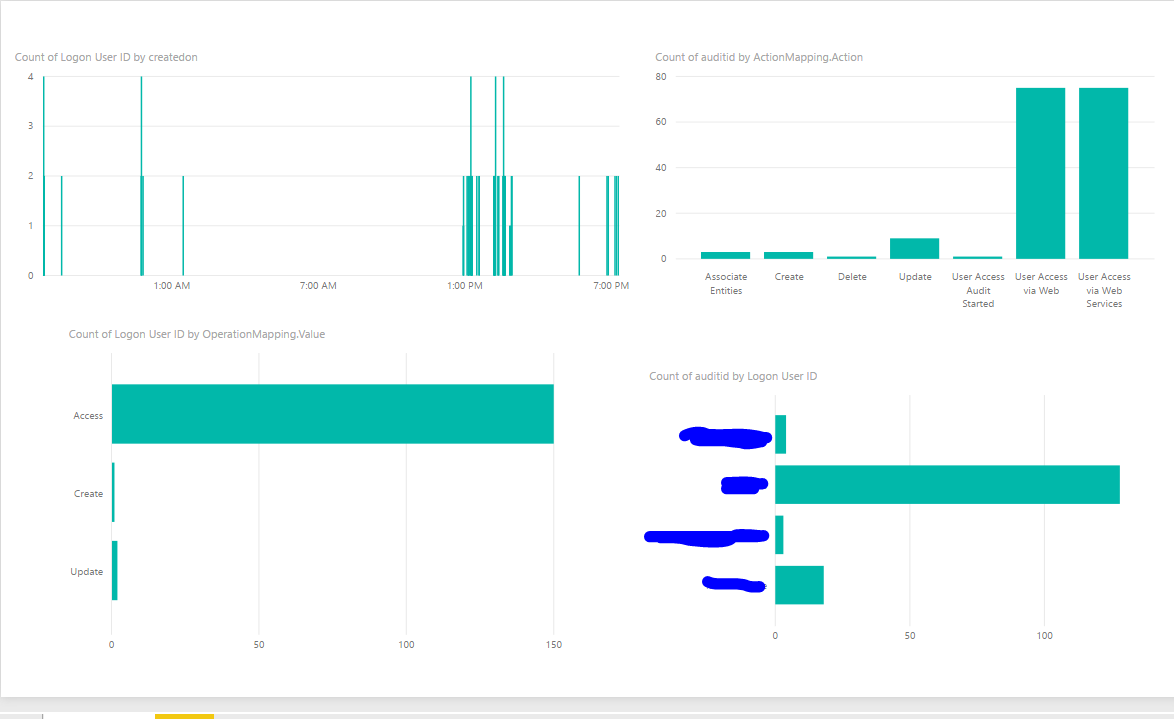
•You can use Power BI to analyze the data in Dynamics 365 (OData or Entity Store from LCS)
•You can Pin your Power BI visuals to Dynamics 365
•You can use existing PowerBI.com solutions from Lifecycle Service
•There is a Power BI Embedded Experience within Dynamics (Boxed)
References:
- Official Doc Configure Dynamics 365 Power BI Integration
- Official Doc: PowerBI.com Service in Dynamics F&O
- Official Doc: Get Dynamics Data in Power BI using Business Central
- Official Doc: Customize Dynamics F&O analytical workspace
In summary, there many other services inside or outside Microsoft products portfolio works will with Power BI. So consider think outside of the box and create different solutions for your business.
Your friend,
Annie


![14a64eeb-b1a7-4a12-889f-8b573c98ef20[1]](https://xuanalytics.com/wp-content/uploads/2018/12/14a64eeb-b1a7-4a12-889f-8b573c98ef201.png)